
Filtres
par
popularité : 14%

X. Commandes et filtres
A. Introduction
Un filtre est une commande qui lit des informations sur l'entrée standard, les traite par ligne, puis qui affiche ses résultats sur la sortie standard :
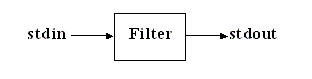
En aucun cas le contenu du fichier d'origine n'est modifié !
Nous connaissons déjà des filtres : cat, more.
Nous allons étudiés quelques autres, la plupart en partie seulement : n'hésitez pas à consulter la man page associée.
B. les commandes head et tail
| head -N fic |
affiche les N premières lignes de fic. |
| tail -N fic |
affiche les N dernières lignes de fic. |
| tail +N fic |
affiche de la ligne N Ã la fin de fic. |
Par défaut, N vaut 10.
C. La commandes wc
wc Compter les lignes, mots et caractères d’un fichier
wc [ -lwc ] fichier
-l nombre de lignes
-w nombre de mots
-c nombre de caractères
exemple:
|
$ wc fic 45 440 3053 fic $ wc -l fic 45 fic $ wc -cw fic 3053 440 fic $ wc toto tutu titi 1 6 29 toto 46 448 3105 tutu 40 462 1773 titi 87 916 4907 total
|
D. La commande find
Elle permet la recherche de fichiers, suivant de multiples critères, à partir d’un (ou plusieurs) répertoire(s). La recherche a lieu dans toute la sous-arborescence. Des notations complémentaires permettent d’effectuer des recherches composées ( ET , OU ).
find répertoire options actions
Quelques options
| -name fichier | Recherche sur le nom ( protéger les caractères spéciaux vis à vis du shell ) |
| -perm mode | Recherche sur les permissions ( masque en octal ) |
| -newer fichier | Recherche des fichiers plus récents qu’un fichier donné |
| -user login | Recherche sur le propriétaire |
| -mtime +n | Fichiers modifiés depuis plus de n jours |
| -mtime -n | Fichiers modifiés depuis moins de n jours |
| -atime +n | Fichiers consultés depuis plus de n jours |
| -atime -n | Fichiers consultés depuis moins de n jours |
|
etc ... |
Actions ( exclusives )
|
Afficher les résultats |
|
| -exec |
Lancer une commande pour chaque fichier trouvé |
| -ok |
Lancer une commande pour chaque fichier trouvé, après demande de confirmation |
Exemples de manipulation de la commande find
|
$ find . -name .??*rc -print UX:find: ERROR: Illegal option -- .mwmrc UX:find: TO FIX: Usage: find path-list predicate-list $ find . -name '.??*rc' -print ./.exrc ./.mwmrc ./.cshrc $ $ find /home -user stage1 -print /home/stage1 /home/stage1/.profile /home/stage1/.rhosts /home/stage1/.exrc /home/stage1/.mwmrc /home/stage1/.xsession /home/stage1/.sh_history /home/stage1/toto /home/stage1/tutu UX:find: ERROR: Cannot read dir /home/ftp/usr: Permission denied UX:find: ERROR: Cannot read dir /home/ftp/etc: Permission denied UX:find: ERROR: Cannot read dir /home/ftp/dev: Permission denied $ Exemples de manipulation de la commande find ( suite ) $ find /home -user stage1 -name '.??*rc' -print /home/stage1/.exrc /home/stage1/.mwmrc UX:find: ERROR: Cannot read dir /home/ftp/usr: Permission denied UX:find: ERROR: Cannot read dir /home/ftp/etc: Permission denied UX:find: ERROR: Cannot read dir /home/ftp/dev: Permission denied $ $ find . \( -name '.??*rc' -o -mtime -1 \) -print . ./.exrc ./.mwmrc ./.sh_history ./main.c $ $ find /home/stage1 /home/stage2 -name '*toto*' -print /home/stage1/toto /home/stage2/toto /home/stage2/toto1 /home/stage2/toto2 $ $ find /home -name .profile -ok wc {} \; < wc ... /home/boss/.profile >? y 20 124 660 /home/boss/.profile < wc ... /home/stage1/.profile >? n < wc ... /home/stage2/.profile >? n < wc ... /home/stage3/.profile >? y 25 39 390 /home/stage3/.profile < wc ... /home/stage4/.profile >? n $
$ find /home -name .profile -exec wc {} \; 20 124 660 /home/boss/.profile 25 39 390 /home/stage1/.profile 25 39 390 /home/stage2/.profile 25 39 390 /home/stage3/.profile 25 39 390 /home/stage4/.profile $ $ find . -name core -ok rm {} \; < rm ... ./core >? y < rm ... ./rep/core >? y $
|
E. la commande sort
sort [options] [ +pos1 [ -pos2 ] ] fichiers...
$ sort -d fic tri suivant l'ordre du dictionnaire.
$ sort -n fic tri numérique.
$ sort -r fic tri en ordre décroissant.
$ sort -u fic conserve une seule occurrence de lignes identiques.
$ sort -t: -k3 fic tri sur le troisième champ (séparateur :)
L’unité de traitement est la ligne ou le mot ( champ ). Le critère de tri par défaut est le code Ascii. De multiples options permettent de choisir des critères plus réalistes ( alphabétique, numérique ... ). Si aucun fichier n'est donné en argument ou si on utilise le caractère - ( signe moins ), la commande traite son entrée standard. Le résultat du tri est écrit sur la sortie standard.
Options usuelles
| -u | Suppression de lignes multiples dans le résultat |
| -o fichier |
Sauvegarde du résultat dans le fichier spécifié ( Ce fichier peut être un des fichiers d'entrée ) |
| -d |
Seuls les lettres, chiffres, espaces et tabulations sont significatifs pour le tri |
| -f |
Minuscules et MAJUSCULES sont confondues |
| -n |
Tri numérique |
| -r |
Résultat en ordre décroissant |
| -tcar | Redéfinition du caractère séparateur |
| -b |
Option quasi-indispensable dans les tris alphabétiques ( pour une bonne gestion du nombre variable d'espaces entre les champs ) |
|
etc... |
Utilisation des champs
Les notations +pos1 [ -pos2 ] permettent d’indiquer que le tri doit s’effectuer uniquement sur certains champs de la ligne. Il est possible d’indiquer plusieurs couples de position pour opérer un tri à plusieurs passes.
Ces positions s’expriment sous la forme m.n éventuellement suivie d'une ou plusieurs options parmi b , d , f , i , n ou r .
m Nombre de champs à sauter depuis le début de la ligne
n Nombre de caractères à sauter depuis le début du champ
Quelques exemples
| sort +1 -2 fichier |
Tri ( critère Ascii ) sur le deuxième champ |
| sort -rn -o fichier +4 -5 fichier |
Tri ( critère numérique, ordre décroissant ) sur le cinquième champ et résultat dans le fichier d’entrée |
| sort -t: +2n -3 /etc/passwd |
Tri du fichier /etc/passwd selon le numéro de «login» ( redéfinition du séparateur de champs ) |
| sort +3.0bf -3.2bf fichier |
Tri sur les deux premiers caractères du quatrième champ ( minuscules et majuscules confondues ) |
| sort +3n -4 +0fb -1 fichier |
Tri sur le quatrième champ ( critère numérique ) puis deuxième passe sur le premier champ ( minuscules et majuscules confondues ) |
F. la commande cut
cut extrait certains champs ou certaines colonnes(1 caractère de large) d'un fichier texte
La commande cut extrait des sous-parties verticales d'un fichier texte.
cut peut travailler sur des champs (séparés par le caractère suivant l'option -d ou par défaut par une tabulation). La plupart des fichiers systèmes d'Unix contiennent des champs séparés par le caractère ':'
cut [ options ] fichiers
Options
| -d car |
Définition du séparateur de champs ( l'espace devra être défini entre "" ) |
| -f liste |
Liste des numéros des champs à extraire |
| -c liste |
Liste des positions des caractères à extraire |
Dans certains cas (tel que la sortie de la commande who) les différentes informations ne sont pas séparées par un caractère spécial mais par un nombre variable de blancs. On est donc amené à utiliser la commande cut sur des colonnes (1 caractère de large).
Exemples :
| $ cut -c12-18,20-25 fich |
récupère les colonnes 12 à 18 et 20 à 25 |
| $ cut -f1,6 -d: /etc/passwd |
extrait les champs 1 et 6 délimités par : |
<
a) Numérotation des colonnes ou des champs
|
A-B |
de A Ã B inclus |
|
A- |
de A Ã la fin (dernier) |
|
-B |
du début (premier) à B |
|
A,B |
A et B |
Exemple :
|
$ cut -d: -f 1,3,6-7 /etc/passwd root:0:/:/sbin/ksh daemon:1:/: bin:2:/usr/bin: sys:3:/: .............. stage1:1001:/home/ecole1:/usr/bin/ksh stage2:1002:/home/ecole2:/usr/bin/ksh .............. $ echo Bonjour cher ami | cut -d" " -f 1,3 Bonjour ami $ $ echo Bonjour cher ami | cut -c 1-3,14-16 Bonami $ $ echo Bonjour cher ami | cut -c 8- cher ami $ |
G. la commande grep
grep recherche des lignes dans un fichier texte et les affiche sur la sortie standard
syntaxe : grep motifRecherché fichier [ fichier2 ...]
Le motif est une expression régulière. Sans autre option , grep retourne l'ensemble des lignes contenant le motif indiqué (même s'il n'est qu'une partie d'un mot).
Ces filtres permettent de rechercher des expressions littérales ou «régulières» dans des fichiers.
Les expressions régulières consistent en un vocabulaire permettant d’exprimer une sémantique puissante de recherche ( voir une première présentation dans le chapitre 3 ).
Les lignes comportant les expressions recherchées sont affichées sur la sortie standard.
Il y a trois filtres :
| grep |
Recherche d'expressions littérales et/ou régulières |
| egrep |
Accepte des expressions plus riches que «grep» |
| fgrep |
Ne traite que des expressions littérales mais est plus compact et performant |
Quelques Options
| -i |
MAJUSCULES et minuscules sont confondues |
| -v |
Les lignes ne comportant pas l'expression |
| -x |
Les lignes exactement identiques à l'expression ( «fgrep» seulement ) |
| -c |
Afficher le nombre de lignes trouvées |
| -l |
Afficher uniquement les noms des fichiers |
| -n |
Chaque ligne est précédée de son numéro dans le fichier |
| -e expr |
Permet de chercher une expression commençant par - ( signe moins )( ne fonctionne pas avec «grep» ) |
| -f fichier |
Les expressions cherchées sont décrites dans un fichier ( une par ligne )( ne fonctionne pas avec «grep» ) |
Quelques Expressions Régulières
| ^ |
Début de ligne |
| $ |
Fin de ligne ( se place en fin d'expression ) |
| . | Présence d’un caractère quelconque |
| [caractères] | Un caractère parmi un ensemble |
| [^caractères] | Un caractère ne figurant pas dans l’ensemble |
car* |
Un nombre quelconque d'apparitions du caractère ( éventuellement 0 ) |
| exp1|exp2 |
Le caractère | signifie OU et relie deux expressions ( egrep ) |
Notations fréquentes et utiles
| ^$ |
Ligne vide ( un début et une fin ) |
| . |
Ligne non vide |
| .* |
«Reste de la ligne» ou «ligne complète» suivant le contexte |
Quelques exemples
| grep '^abc' fichier |
Lignes commençant par la chaîne «abc» |
| grep '^[abc]' fichier |
Lignes commençant par a ou b ou c |
| grep ‘^[^0-9]’ fichier |
Lignes ne commençant pas par un chiffre |
| grep 'abc.$' fichier |
Lignes se terminant par la chaîne «abc» suivie d’un caractère quelconque |
| fgrep -f motifs fichier |
Recherche des expressions littérales indiquées dans le fichier «motifs» |
| grep -n '^' fichier |
Numéroter toutes les lignes ( toutes les lignes ont un début ) |
| grep -i 'toto *$' fichier |
Lignes se terminant par la chaîne «toto» ( minuscules ou majuscules ) suivie d’un nombre quelconque d’espaces |
| egrep '^abc|ef *$' fichier | Lignes commençant par la chaîne «abc» ou bien se terminant par la chaîne «ef» suivie d’un nombre quelconque d’espaces ( Penser à invoquer "egrep" , grep ne connaît pas le signe | ) |
H. La commande tr
Ce filtre lit l'entrée standard pour effectuer des substitutions ou des suppressions de caractères.
Les résultats sont écrits sur la sortie standard.
tr [options] [ chaine1 [ chaine2 ] ]
Dans la syntaxe de base, les caractères mentionnés dans «chaine1» sont remplacés par ceux de même position dans «chaine2».
Des abréviations sont possibles pour désigner des ensembles de caractères :
| [a-z] | Les lettres minuscules ( intervalle ) |
| [a*n] | n fois le caractère a ( * seul signifie : «un nombre quelconque» ) |
| \xyz |
Code Ascii en octal du caractère |
Options
| -d |
Supprimer les caractères apparaissant dans «chaine1» |
| -s |
Les caractères consécutifs identiques sont réduits à un seul exemplaire |
| -c |
Négation -> Les caractères n'apparaissant pas dans «chaine1» |
Quelques exemples
| tr "[a-z]" "[A-Z]" < fichier |
Transformer les minuscules en MAJUSCULES. |
| tr -sc "[A-Z][a-z]" "[\012*]" < fichier |
Les caractères non alphabétiques sont transformés en un saut de ligne. Les sauts de ligne consécutifs sont éliminés. On obtient un mot alphabétique par ligne. |
| tr -d "abcd" < fichier |
Les caractères a , b , c et d sont supprimés. |
I. La commande sed
Ce filtre est un éditeur non interactif qui copie les fichiers d'entrée sur la sortie standard après leur avoir appliqué un certain nombre de commandes.
sed [-n] 'commandes_sed' fichiers...
ou
sed [-n] -f fichier_commandes fichiers...
Syntaxe des commandes sed et principe de fonctionnement
[ adresse1 [,adresse2] ] action [ arguments ]
Les crochets indiquent un aspect facultatif et n’apparaissent pas dans les commandes. Tous ces éléments ne sont séparés par aucun espace. En l’absence d’adresses de sélection, l’action a lieu sur toutes les lignes des fichiers d’entrée. L’action par défaut est d’afficher la ligne sur la sortie standard.
L'option -n permet de supprimer cette sortie systématique des lignes.
Une adresse peut être, entre autres :
- Un numéro de ligne
- Le caractère $ désignant la dernière ligne
- Le caractère . ( point ) désignant la ligne courante
- Une expression littérale ou régulière entre deux caractères /
Quelques actions usuelles
| d |
Ne pas afficher la ligne |
| p |
Afficher la ligne ( s’utilise souvent avec l'option -n ) |
| q |
Abandonner le traitement |
| s/expr1/expr2/ |
Remplacer la première expression par la seconde,une seule fois par ligne |
| s/expr1/expr2/g |
Remplacer la première expression par la seconde, plusieurs fois par ligne si nécessaire |
| s/expr1// |
Supprimer l'expression |
| s/expr1/...&.../ |
Remplacer la première expression par elle-même plus «quelque chose» ( La notation & signifie : «reprendre la première expression» ) |
| = |
Afficher le numéro de ligne |
etc...
Quelques exemples
| sed 's/monsieur/madame/g' fichier |
Remplacer une chaîne par une autre plusieurs fois par ligne |
| sed 's/^/ /' fichier |
Décaler le début de chaque ligne par des espaces |
| sed '/./s/^/ /' fichier |
Idem uniquement sur les lignes non vides |
| sed -n '/expression/!p' fichier | Afficher les lignes ne contenant pas l’expression ( Le ! indique la négation de l’expression ) |
| sed -n '20,30p' fichier |
Afficher les lignes de numéro 20 à 30 |
| sed '1,10d' fichier |
Ne pas afficher les 10 premières lignes |
| sed -n '/./p' fichier |
Afficher uniquement les lignes non vides |
| sed '/^$/d' fichier |
Même traitement |
| sed '/expression/q' fichier |
Afficher jusqu’à une expression donnée |
| sed -n '/expression/=' fichier |
Afficher les numéros des lignes contenant une expression donnée |
| sed 's/toto/bonjour &/g' fichier |
Remplacer la chaîne «toto» par «bonjour toto», |
J. La commande awk
Cet utilitaire awk tire son nom de ceux de ses concepteurs. ( Alfred AHO , Peter WEINBERGER , Brian KERNIGHAN )
C'est un outil très adapté pour réaliser des tâches de manipulation de données sans avoir à les programmer dans un langage classique comme le C. En effet, beaucoup de choses sont implicitement résolues. ( les entrées, la gestion des «champs», la gestion mémoire, les déclarations, les initialisations ... )
Syntaxe et principe de fonctionnement
awk 'liste-de-commandes' fichiers...
ou
awk -f fichier_commandes fichiers...
Une commande est constituée ainsi : motif { action }
Le «motif» sert d’expression de sélection des lignes pour y appliquer l’action associée. Si le motif est absent, toutes les lignes sont concernées par l’action. L’action par défaut consiste à afficher la ligne.
Chaque ligne d'entrée est automatiquement divisée en «champs». Les différents champs sont nommés respectivement : $1 $2 $3 ... $NF
NF représente le nombre de champs de la ligne en cours de traitement. Le séparateur de champs peut être positionné à un caractère particulier.
Pour ce faire, on peut procéder de deux façons :
1) On utilise comme première commande : BEGIN { FS = "caractère" }
ou
2) A l'appel de «awk», on utilise l'option -Fcaractère
D’autres variables intéressantes sont prédéfinies :
$0 La ligne entière
NR Numéro de la ligne courante
FILENAME Nom du fichier courant d'entrée
etc...
Les motifs
Les programmes peuvent souvent se résumer à une suite de motifs puisque l'action par défaut est l'impression des lignes sélectionnées.
«awk» est donc un outil très puissant de sélection.
Quelques motifs possibles
- Expression bâtie avec des opérateurs très proches de ceux du langage C
$3 < 10
$3 < $2 + 10 && $4 == "dupont"
- Expression littérale ou régulière entre deux caractères /
/dupont/
/^[0-9]/
- Intervalle de numéros de lignes
NR == 10 , NR == 15
- Le motif BEGIN
L’action associée est exécutée avant le traitement des fichiers d’entrée
- Le motif END
L’action associée est exécutée après le traitement des fichiers d’entrée
Les actions
Une action est une suite d'instructions.
Chaque instruction est terminée par un ; ( point-virgule ) ou un saut de ligne.
Instructions disponibles
- Les fonctions d'affichage «print» ( affichage brut ) et «printf» ( affichage formaté )
- Instruction bâtie avec des opérateurs très proches de ceux du langage C
- Instructions de contrôle ( tests, boucles, fonctions intégrées ... )
Quelques exemples
| awk ' $3 > 1000 { print $1 , $2 , $3 } ' fichier |
Pour toutes les lignes où le troisième champ est supérieur à mille, on affiche la valeur des trois premiers champs |
| awk ' { print NR , $0 } ' fichier |
Numéroter les lignes d’un fichier |
| awk ' { printf "%4d %s\n" , NR , $0 } ' fichier |
Même traitement avec formatage |
|
awk ‘ $3 > 1000 { val++ } END { print val } |
Afficher le nombre de lignes où le ‘ fichier troisième champ est supérieur à 1000 |
|
awk ‘ $3 > max { max = $3 ; maxnom = $2 } END { print max , maxnom } |
Afficher la valeur maximum ‘ fichier du troisième champ ainsi que celle du deuxième champ associé |
|
awk ‘ { noms = noms $2 " " } END { print noms } |
Afficher la concaténation ‘ fichier de tous les deuxièmes champs ( L’espace est l’opérateur de concaténation ) |
|
awk ‘ BEGIN { printf "Calcul du maximum et de la moyenne\n" } { somme += $3 } $3 > max { max = $3 } END { printf "Maximum = %10.2f Moyenne = %10.2f \n" , max , somme / NR } ‘ fichier |
Commentaires Forum fermé